
Регулярные выражения
Обработка регулярным выражением полученных данных доступна уже давно, благодаря такой сногсшибательной функциональности Fenom. А с версии 1.3.0 регулярки были внедрены:
- в конфигурацию задания при указании записи селектора,
- в поля источника.
Пользователю это даёт более гибкую выборку записей из источника.
Пример
Опишу пример того, как я извращался при помощи регулярок в xParser.
Дано
Возникла потребность распарсить сайт, имеющий странную структуру записей. На CSS или XPath синтаксисе к ним было не подобраться. Пример странной структуры:
html
<div class=content>
<p>
<h2>Какой-то заголовок</h2>
Текст с описанием раздела
<p>
18.01.10 <a href="http://domain.zone/link1.html">Запись 1</a>
<br>Описание записи 1
<p>
24.12.09 <a href="http://domain.zone/link2.html">Запись 2</a><br>
Описание записи 2
<p>
23.12.09 <a href="http://domain.zone/link3.html">Запись 3</a>
<br>Описание записи 3
<p>
22.12.09 <a href="http://domain.zone/link4.html">Запись 4</a><br>
Описание записи 4
...
</div>Что мы имеем
- Запись не содержится в отдельном контейнере. Отсюда сложность получить ее. Решаемо за счет регулярки!
- Теги
<p>в каждой записи открыты, но не закрыты. Решается внутренними средствами xParser без вашего участия! - Тег
<br>может стоять, как сразу после ссылки, так и на следующей строке под ней. Решаемо за счет регулярки!
Версия xParser ниже 1.3.0 не справлялась с этим, честно скажем...
Выборка записи
Как обычно, мы создаем задание. Только теперь при указании селектора записи в конфигурации задания, мы можем выбрать синтаксис, среди которых: CSS, XPath, RegExp. Нам нужны регулярные выражения!
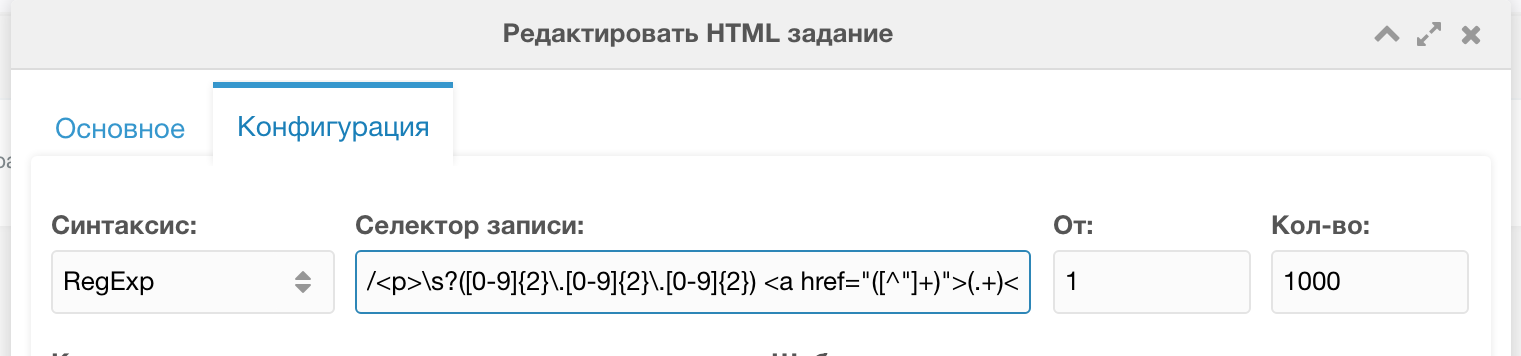
Вот такую регулярку я составил для выборки записей из странной структуры:
php
/<p>\s?([0-9]{2}\.[0-9]{2}\.[0-9]{2}) <a href="([^"]+)">(.+)<\/a>\s?<br>\s?(.*)\s?<\/p>/uiТаким образом мы получим каждую запись на странице. Всего их было около 100 шт.
Поля источника
После чего нам надо распарсить поля источника. Это я тоже реализовал на регулярных выражениях:
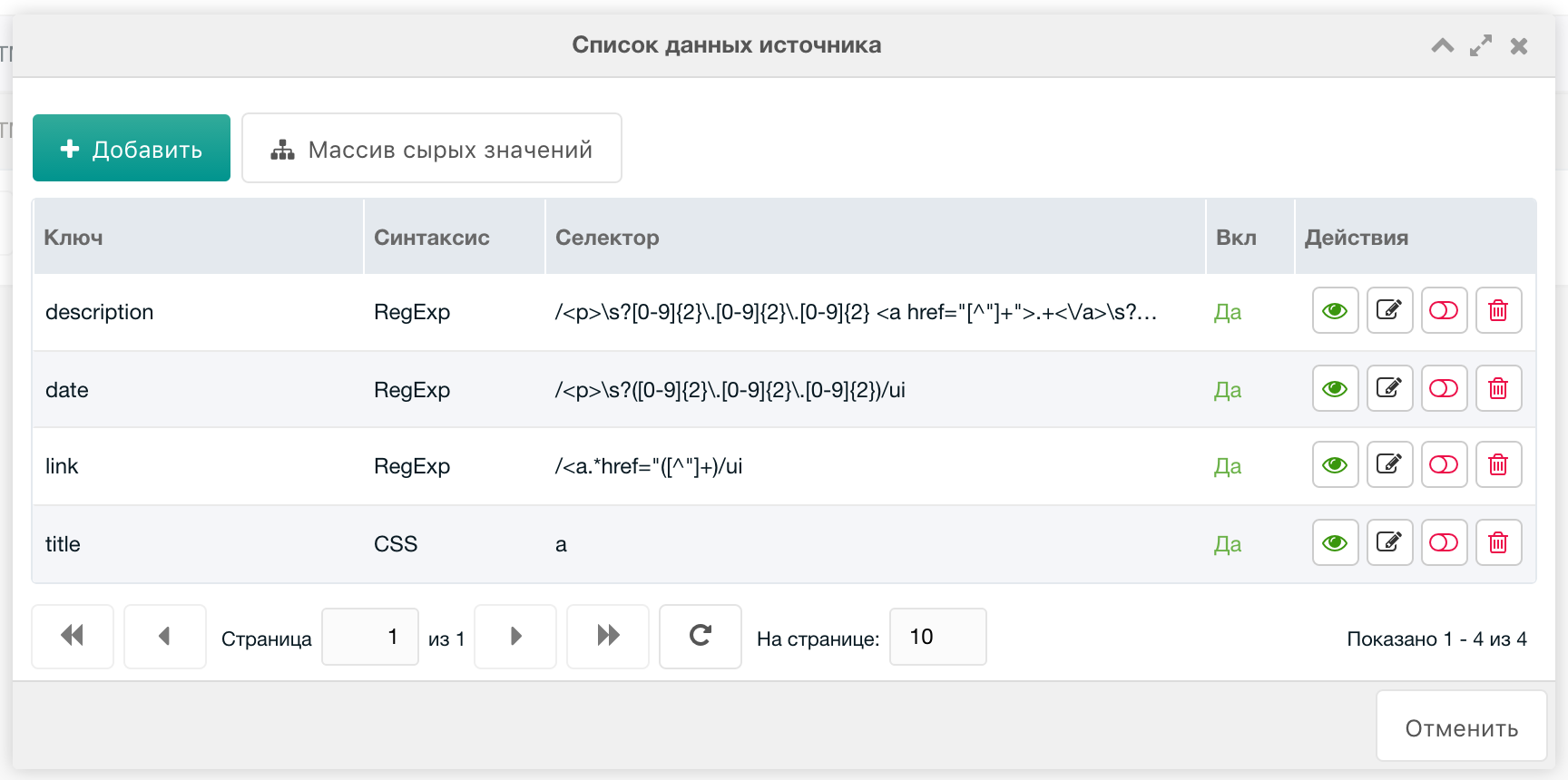
Ссылка
- Синтаксис =
RegExp - Ключ =
link - Селектор:
/<a.*href="([^"]+)/ui
Дата
- Синтаксис =
RegExp - Ключ =
date - Селектор =
/<p>\s?([0-9]{2}\.[0-9]{2}\.[0-9]{2})/ui
Описание
- Синтаксис =
RegExp - Ключ =
description - Селектор =
/<p>\s?[0-9]{2}\.[0-9]{2}\.[0-9]{2} <a href="[^"]+">.+<\/a>\s?<br>\s?(.*)\s?<\/p>/ui
Итого
С помощью регулярных выражений можно парсить даже самую сложную структуру. Поэтому всем советую изучать регулярки, хотя бы на том уровне, на котором знаю их я.