
Парсер HTML контента + Совмещенные задания
Прежде всего стоит прочесть о настройке задания для RSS лент. Там основная суть работы компонента.
Совмещение заданий
С версии 1.2.0 компонент умеет совмещать задания. Например, вам нужно распарсить RSS ленту и каждую запись выпилить с сайта полностью. Для этого:
- Создаётся пара заданий (первое — RSS, второе — HTML),
- Настраивается,
- Запускается.
Ниже разберемся подробнее, как и что нужно делать для совмещения заданий.
Парсинг HTML контента
Так как в RSS ленте у нас, по-умолчанию, присутствует некий массив полей, которые можно распределить по полям MODX, то в HTML дела обстоят несколько сложнее: нам нужно самим создать эти поля, указав селектор до каждого из них. Давайте на примере MODX.pro рассмотрим, как это делается:
Добавление заданий
Покажу пример, в котором происходит запуск одного задания из другого. Для этого нам надо будет создать 2 задания:
Добавление primary задания
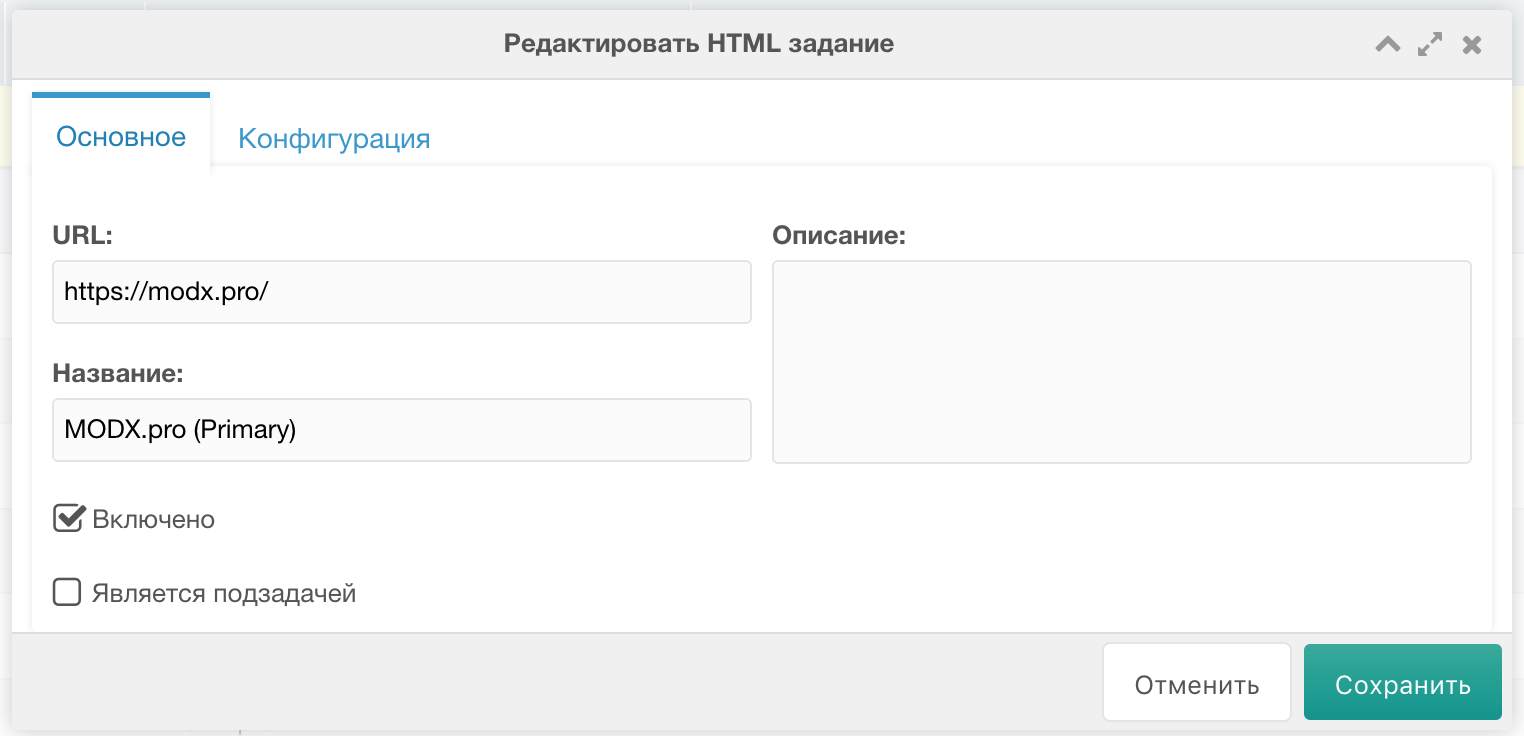
Primary заданием я называю список новостей, которые нам необходимо распарсить.
Жмём "Добавить HTML задание". На вкладке "Основное" заполняем примерно так:
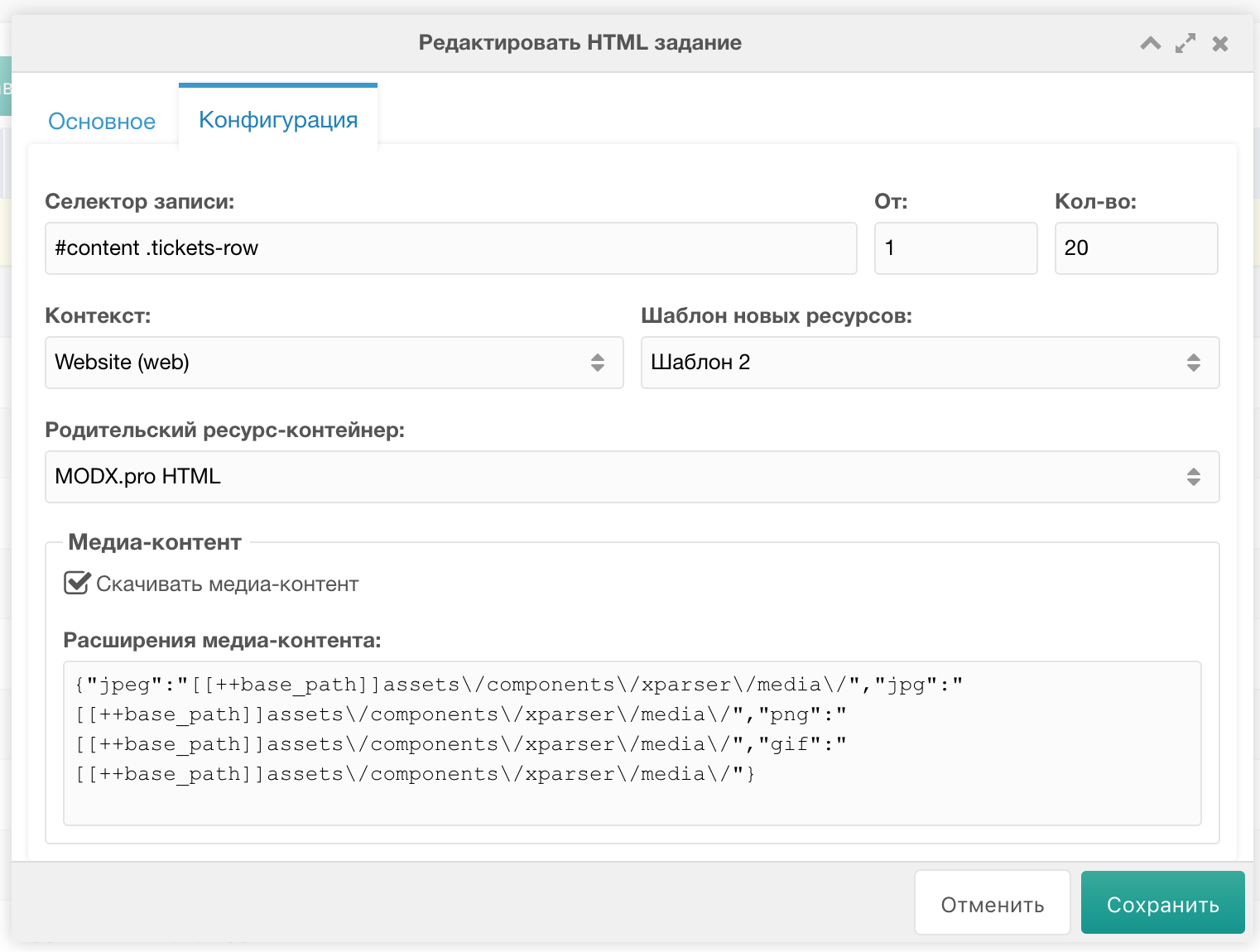
Переключаемся на вкладку "Конфигурация", где указываем:
- Селектор записи (пока только CSS-подобный синтаксис),
- С какой по счёту записи стартовать,
- Сколько записей парсить,
- Шаблон для создаваемых ресурсов,
- Контекст,
- Родительский контейнер в пределах выбранного контекста,
- Скачивать ли медиа-контент.
Жмём "Сохранить" - задание добавлено!
Добавление secondary задания
Secondary заданием я называю задание, с настройкой парсинга для полной статьи. Его мы будем указывать в качестве наследника для первого задания.
Жмём "Добавить HTML задание". На вкладке "Основное" заполняем примерно так:
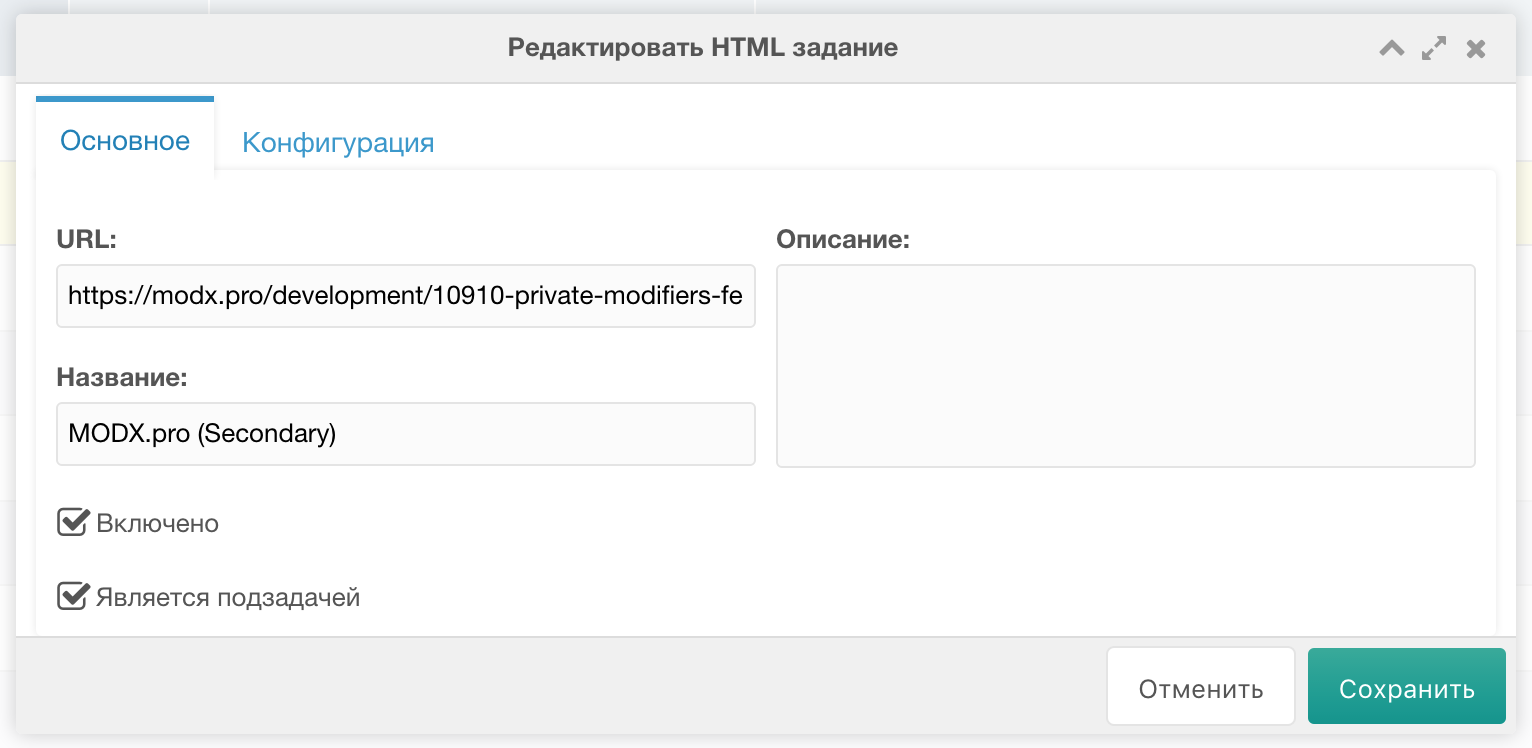
Важно указать
- URL - ссылку на какую-нибудь статью с modx.pro (потребуется для настройки полей источника),
- Поставить галочку Является подзадачей.
Переключаемся на вкладку "Конфигурация", где указываем:
- Селектор записи =
#content
Настройка источника
Так как задания у нас типа HTML, то придётся вручную создавать данные источника, которые будем парсить. Потребуется сделать это для обоих заданий.
Жмём на задании правой мышью => "Источник".
Настройка источника для primary задания
Здесь достаточно добавить всего 1 поле - ссылку на полную версию статьи. Однако, я предлагаю добавить ещё и поле content, в котором будет храниться вступительная часть статьи. В этом вступительном тексте также указывается основное изображение статьи, вот его то мы и будем выдирать с помощью регулярки. Происходить это будет на шаге Настройки полей primary задания.
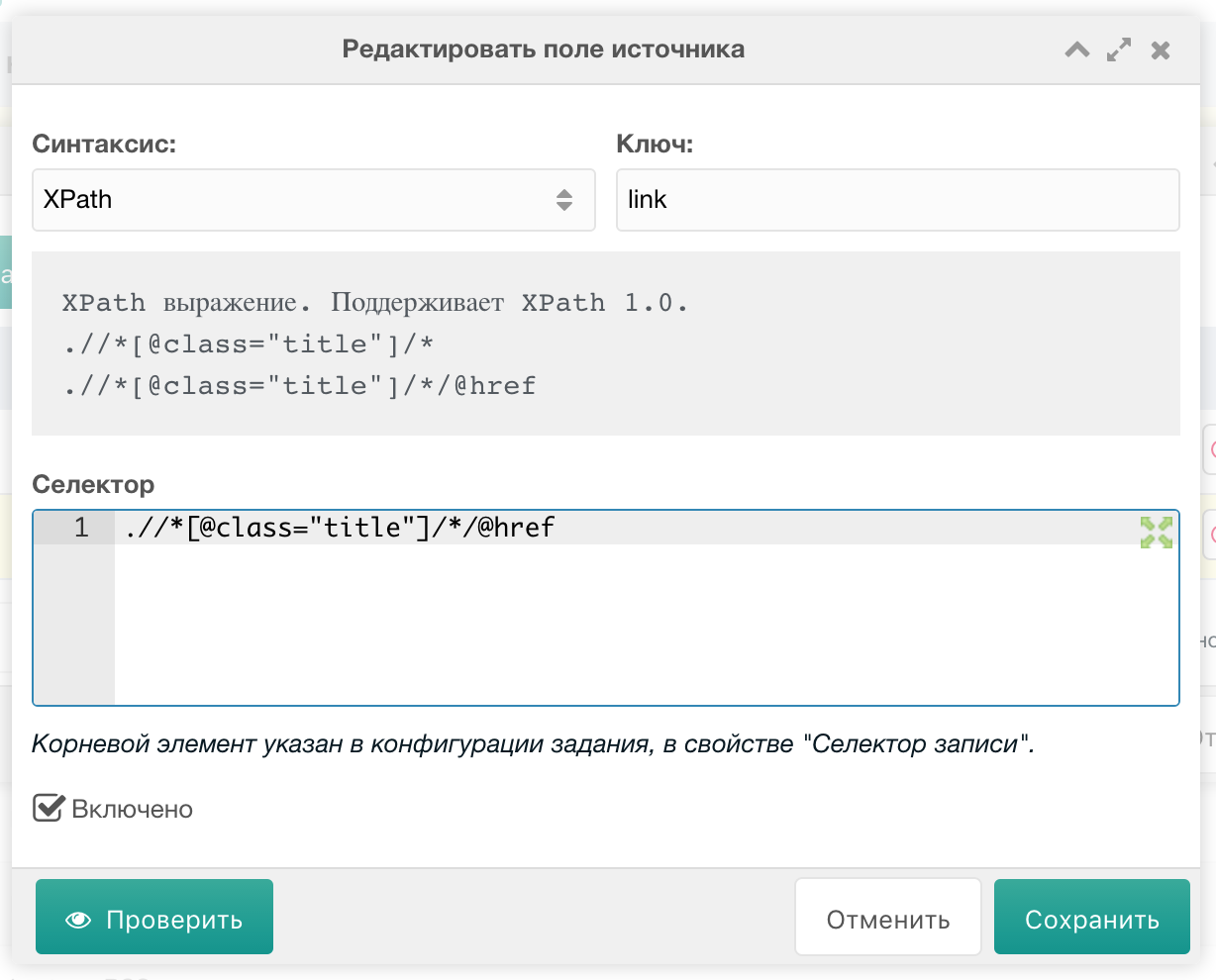
Жмём "Добавить". Здесь у нас есть возможность указать CSS-подобный или XPath синтаксис. Для разных полей часто требуется и тот, и другой.
Внимание
XPath синтаксис имеет неприятный баг: не понимает названия тегов, поэтому приходится указывать тег, как *.
Заполняем примерно так:
Там же можно проверить, насколько корректно парсер получает указанные нами значения. Для этого требуется нажать на кнопку с глазом:

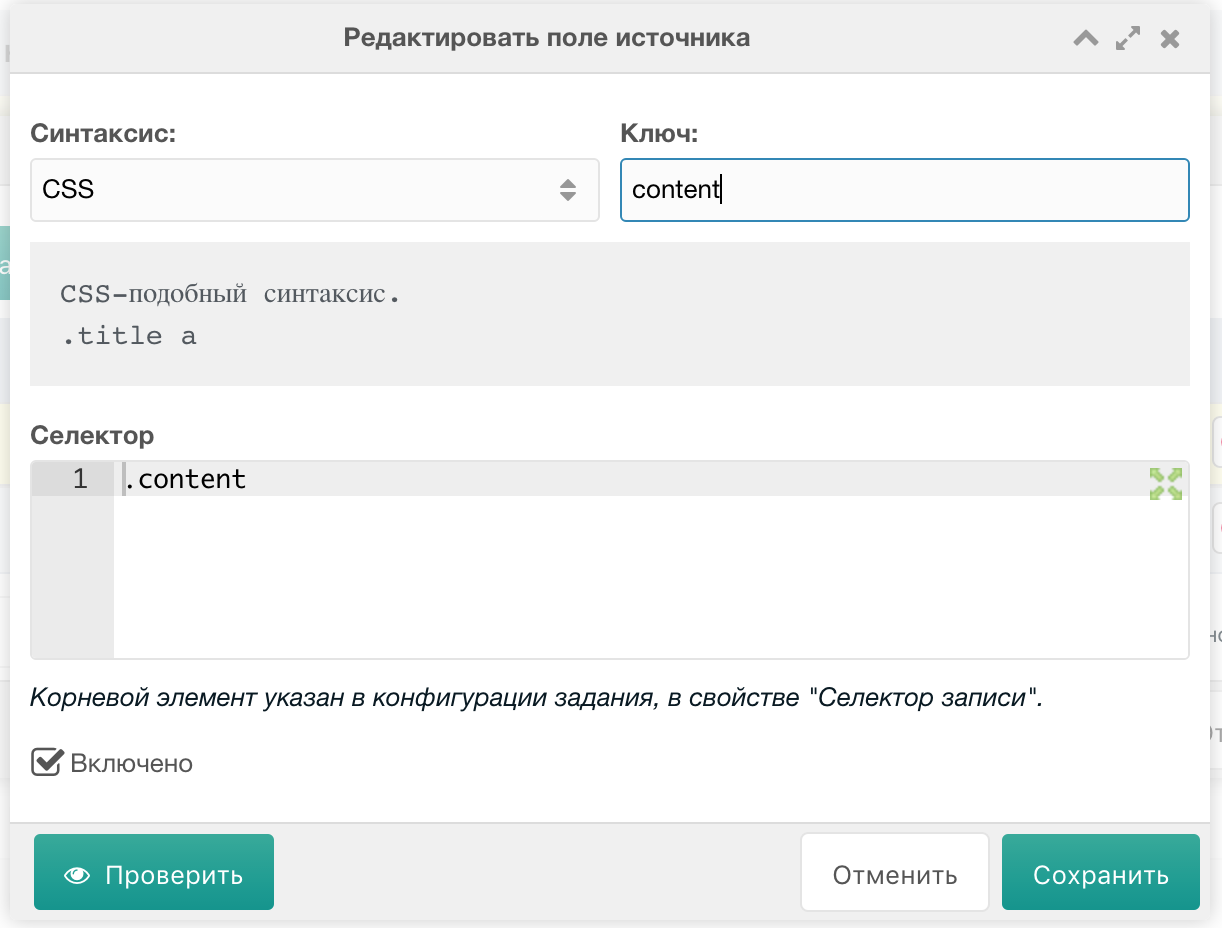
Настройка источника для secondary задания
Тут мы добавляем, также, 2 поля:
Pagetitle
- Синтаксис =
CSS - Ключ =
pagetitle - Селектор =
h3.page-title
Content
- Синтаксис =
CSS - Ключ =
content - Селектор =
.page-content
Настройка полей задания
По большому счёту тут всё очень похоже на настройку RSS задания, т.к. у нас уже есть данные из источника, которые можно просмотреть в виде распечатанного массива, кликнув по кнопке "Массив сырых значений".
Сейчас нам надо, опираясь на эти ключи и значения источника, правильно добавить поля для парсинга. Жмём на задании правой мышью => "Поля".
Описывать подробно возможности пакета на данном этапе не буду, кому интересно, может почитать это в описании настройки RSS заданий.
Настройка полей primary задания
Здесь тоже достаточно одного поля link, но мы добавим и поле с основным изображением поста. Выдернем это изображение из вступительной части статьи с помощью Fenom и регулярного выражения.
Жмём "Добавить".
Link
- Системное поле = пусто
- Поле в источнике =
link - Значение по-умолчанию = пусто
Introtext: (запишем сюда изображение)
- Системное поле =
resource | introtext - Поле в источнике =
@INLINE {$content | preg_get : '!https?://.+\.(?:jpe?g|png|gif)!Ui'} - Значение по-умолчанию = пусто
Теперь, в таблице добавленных полей задания, у поля link, кликаем на звезду (поле должно стать оранжевым) и на соседнюю кнопку. Откроется окошко добавления связанного задания. Там есть сноска, продублирую:
- Убедитесь, что выбранное поле действительно является ссылкой.
- При парсинге эта ссылка будет передана в задание, которое вы выбрали ниже.
- Из выбранного задания будут получены все поля для создания объекта.
- Полученные поля перезапишут аналогичные поля из текущего задания.
В поле "Принимающее задание" выбираем наше secondary задание. Таким образом, primary задание передаст УРЛ из поля link в secondary задание.
Жмём "Сохранить".
Поле link в таблице подсветится синим цветом:

Настройка полей secondary задания
Тут добавляем 3 поля:
Pagetitle
- Системное поле =
resource | pagetitle - Поле в источнике =
@INLINE {$pagetitle | preg_replace : '! \<sup class.*!ui'} - Значение по-умолчанию = пусто
Content
- Системное поле =
resource | content - Поле в источнике =
content - Значение по-умолчанию = пусто
Published
- Системное поле =
resource | published - Поле в источнике = пусто
- Значение по-умолчанию =
1
Сохраняем!